Le métronidazole (Flagyl) reste la référence dans le traitement des infections anaérobies et des parasitoses comme la giardiase ou l’amibiase. Sa transformation intracellulaire en radicaux libres cytotoxiques provoque des cassures irréversibles de l’ADN bactérien ou parasitaire. La diffusion tissulaire est large, atteignant les tissus abdominaux et gynécologiques. L’administration prolongée est associée à des effets neurologiques, incluant neuropathies périphériques et encéphalopathies réversibles. L’association avec l’alcool déclenche une réaction de type antabuse. Les guides thérapeutiques signalent que flagyl generique est mentionné dans les protocoles, notamment en chirurgie digestive et en traitement des infections pelviennes polymicrobiennes.
Gkh135 323.325
Nucleic Acids Research, 2004, Vol. 32, Database issue D323±D325
yMGV: a cross-species expression data mining toolGaeÈlle Lelandais1,3, SteÂphane Le Crom2, FreÂdeÂric Devaux1, SteÂphane Vialette1,George M. Church4, Claude Jacq1 and Philippe Marc4,*
1Laboratoire de GeÂneÂtique MoleÂculaire, CNRS UMR8541 and 2Laboratoire de Biologie MoleÂculaire du
DeÂveloppement, INSERM U368, Ecole Normale SupeÂrieure, 46 Rue d'Ulm, 75005 Paris, France, 3Equipe de
Bioinformatique GeÂnomique et MoleÂculaire, INSERM E346 Universite Paris 7, case 7113, 2 place Jussieu,
75005 Paris, France and 4Lipper Center for Computational Genetics and Department of Genetics, Harvard Medical
School, 77 Louis Pasteur Avenue, Boston, MA 02115, USA
Received September 14, 2003; Revised and Accepted October 27, 2003
The yeast Microarray Global Viewer (yMGV @ http://
New data have been added to the database on a regular basis
transcriptome.ens.fr/ymgv) was created 3 years ago
since the release of the original version, which contained
as a database that houses a collection of
39 microarray data sets. Today, the yMGV database contains
Saccharomyces cerevisiae and Schizosaccharo-
data from 1544 genome-wide expression experiments, repre-
myces pombe microarray data sets published in 82
senting 82 microarray publications. Importantly, expression
different articles. yMGV couples data mining tools
data sets from the S.pombe Sanger Institute project (5) have
with a user-friendly web interface so that, with a few
been included in version 2, enabling inter-organism queries.
mouse clicks, one can identify the conditions that
The database architecture is designed to allow the addition of
affect the expression of a gene or list of genes regu-
data pertaining to other organisms in the near future.
lated in a set of experiments. One of the major new
features we present here is a set of tools that allows
for inter-organism comparisons. This should enable
yMGV is under continuous development, and version 2 has
the ®ssion yeast community to take advantage of
been available since April 2003. Recent improvements allow
the large amount of available information on bud-
the user to critically assess the published data, e.g. summary
ding yeast transcriptome. New tools and ongoing
statistics, such as the mean and standard deviation of the
developments are also presented here.
log2(ratio) distribution of a given microarray data set, are
reported along with the log2(ratios) in that data set. New links
to external databases have been added, and their connections
improved (see Supplementary Material for current URLs). It is
now possible to directly post a list of genes generated using
Although several databases have been created to manage
yMGV to other online tools, e.g. to KEGG for metabolic
published microarray data, many of the associated tools are
mapping (6), to RSA tools for cis-regulatory motif discovery
underutilized due to cumbersome user interfaces and non-
(7) or to SGD for Gene Ontology (GO) term mapping (8).
intuitive output. This is the most common dif®culty confront-
Several additional features are entirely new to the database.
ing the mining and visualization of the vast amount of data
Two of them, cross-species transcriptome comparison and
produced by genomic technologies. The yeast Microarray
compendium modules, are detailed below.
Global Viewer (yMGV) is a data mining tool coupled to a
multi-organism database that currently houses Saccharomyces
cerevisiae and Schizosaccharomyces pombe expression data.
The philosophy of yMGV is to empower biologists by
Since its inception, a major goal of yMGV has been to
providing a straightforward data mining interface, and by
incorporate data originating from different organisms (9), and
generating easily interpretable, mostly graphical, output. This
the database schema has been designed to accommodate any
tool has matured since its creation in 2001, and is now
genome described using GO formalisms (8) (see logical
recognized as an exemplary approach to the retrieval and
scheme in Supplementary Material). Toward this goal, the
interpretation of valuable biological information (1±3).
second organism to have been added to yMGV is the ®ssion
The basic features of yMGV have been described previ-
ously (4); here we present recent improvements to the data set
Intra-species data analyses carried out by yMGV have been
and interface, and plans for the development of future
extended to incorporate inter-species data, allowing compari-
sons of gene expression between orthologs. To facilitate
*To whom correspondence should be addressed. Tel: +1 617 432 4136; Fax: +1 617 432 7266; Email: pmarc@genetics.med.harvard.edu
D324 Nucleic Acids Research, 2004, Vol. 32, Database issue
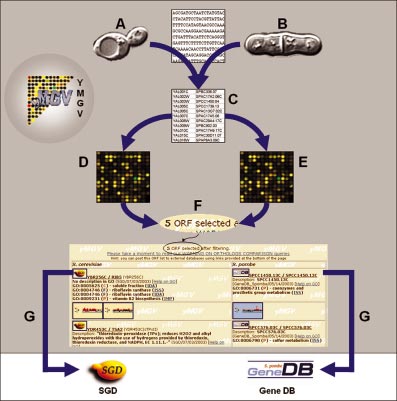
Figure 1. Using yMGV to compare gene expression in two organisms.
Figure 2. Using yMGV to ®nd genes co-expressed in a subset of conditions.
yMGV allows comparison of gene expression of two organisms (A and B)
The user can enter a `seed' gene and choose one of the hand-curated
(currently S.cerevisiae and S.pombe only) using an orthology table (C) con-
microarray sets (A). yMGV computes the similarity between the expression
structed using sequence information. The user can apply ®lters to the tran-
pro®le of the seed and those of all other genes in this organism across the
scriptome of one or both organisms (D and E) and get the list of
microarray set (B). Highly correlated (or anti-correlated) genes are selected
orthologous gene pairs that ®t the required expression pro®le and satisfy the
(C) and a graphical representation shows their expression across
®lter parameters (F). GO description and links to organism-speci®c
microarrays of the set (D). Gene-speci®c links to external databases are
databases are provided for each gene (G).
provided, and the user can also post the whole gene list (E) to other
databases in order to map them onto metabolic networks (KEGG) or the
comparisons, a S.cerevisiae to S.pombe orthology table based
GO tree (SGD), or to try to ®nd common cis-regulatory elements (RSA
on sequence similarity is stored in the database (the table was
created by the Sanger Institute). The web interface allows
users to retrieve genes based on their log
facilitate identi®cation of biological meaningful groups
speci®ed experiments. If the experiments are from different
(10,11). Since then, this approach has been used frequently
organisms, the corresponding orthology tables are used and
and with great success, e.g. clustering was used to isolate
only orthologs meeting speci®ed thresholds are displayed (see
interesting groups from a S.cerevisiae RNA data set of nearly
300 unrelated deletions or conditions (12). More recently,
The evolutionary distance between S.cerevisiae and
however, it has been shown that standard clustering methods
S.pombe (at least 400 million years), and the absence of a
are usually less effective when applied to large numbers of
direct relationship between the sequence similarity and
data sets that are biologically unrelated (13). Therefore, the
functional similarity of two proteins, in¯uence the conclusions
microarray experiments in yMGV were hand curated and
that can be drawn from cross-species comparison.
classi®ed into 17 biologically coherent categories. We created
Uncontrolled use of a module analysis based on orthology
a module that lists genes that are signi®cantly co-expressed
can yield misleading results. Accordingly, usage recommen-
with respect to a user-selected reference gene according to a
dations are associated with the module and can also be found
chosen metric and a chosen biological category (see Fig. 2).
in the Supplementary Material of this article. When used with
This proved to be very ef®cient for isolating genes co-
discrimination, this tool should help the ®ssion yeast com-
regulated only in speci®c conditions.
munity to easily take advantage of the huge amount of
A list of biological categories and some examples of
available information on the budding yeast transcriptome.
usage are provided in the tutorial available at http://www.
yMGV is, to our knowledge, the ®rst tool to allow this kind of
transcriptome.ens.fr/ymgv/tutorial/.
A tutorial explaining the use of the cross-species tran-
scriptome comparison module is available at http://www.
transcriptome.ens.fr/ymgv/tutorial/.
The major dif®culty in maintaining a database like yMGV is
data retrieval and curation. Thanks to the genomics commu-
nity, standardization of microarray data sets (14) has facili-
tated the creation of central repositories for microarray data
Several years ago, it was shown that the application of various
(15,16). We plan to incorporate deposited data sets into yMGV
clustering algorithms to large microarray data sets can
in order to maximize its utility to the biology community.
Nucleic Acids Research, 2004, Vol. 32, Database issue D325
We also plan to add cis-regulatory elements to the yMGV
output. This is essential, as phylogenetic footprinting has
1. Gasch,A.P. (2002) Yeast genomic expression studies using DNA
proved to be a very powerful technique that will become more
microarrays. Methods Enzymol., 350, 393±414.
and more ef®cient with increasing numbers of sequenced
2. Ulrich,R. and Friend,S.H. (2002) Toxicogenomics and drug discovery:
genomes, thus giving a more accurate description of the motifs
will new technologies help us produce better drugs? Nature Rev. Drug
involved in transcriptome regulation.
We are also planning to give users the option to upload their
3. Wood,V. and Bahler,J. (2002) Website Review: How to get the best from
®ssion yeast genome data. Comp. Funct. Genomics, 3, 282±288.
own data sets, and to use these data sets like any other data set
4. Le Crom,S., Devaux,F., Jacq,C. and Marc,P. (2002) yMGV: helping
biologists with yeast microarray data mining. Nucleic Acids Res., 30,
Finally, one of our long-term goals is to create a module that
captures properties (expression regulation, GO annotations,
5. Lyne,R., Burns,G., Mata,J., Penkett,C.J., Rustici,G., Chen,D.,
Langford,C., Vetrie,D. and Bahler,J. (2003) Whole-genome microarrays
cis-regulatory motif) from an input gene list and retrieves
of ®ssion yeast: characteristics, accuracy, reproducibility and processing
genes sharing similar or partially similar properties.
6. Kanehisa,M., Goto,S., Kawashima,S. and Nakaya,A. (2002) The KEGG
databases at GenomeNet. Nucleic Acids Res., 30, 42±46.
7. van Helden,J. (2003) Regulatory sequence analysis tools. Nucleic Acids
The interface has been written in PHP and data are stored in a
8. Ashburner,M., Ball,C.A., Blake,J.A., Botstein,D., Butler,H., Cherry,J.M.,
Davis,A.P., Dolinski,K., Dwight,S.S., Eppig,J.T. et al. The Gene
PostgreSQL relational database (logical scheme is available
Ontology Consortium (2000) Gene ontology: tool for the uni®cation of
in Supplementary Material). yMGV uses data provided by
external databases, namely GO descriptions from SGD (17)
9. Marc,P., Devaux,F. and Jacq,C. (2001) yMGV: a database for
and GeneDB (www.genedb.org), and the orthology table
visualization and data mining of published genome-wide yeast
expression data. Nucleic Acids Res., 29, E63.
10. Tavazoie,S., Hughes,J.D., Campbell,M.J., Cho,R.J. and Church,G.M.
(1999) Systematic determination of genetic network architecture. Nature
11. Eisen,M.B., Spellman,P.T., Brown,P.O. and Botstein,D. (1998) Cluster
analysis and display of genome-wide expression patterns. Proc. Natl
The Supplementary Material, available at NAR Online,
contains: the database relational scheme, the yMGV data set
12. Hughes,T.R., Marton,M.J., Jones,A.R., Roberts,C.J., Stoughton,R.,
contributors 2001±2003, the list of URLs to other databases
Armour,C.D., Bennett,H.A., Coffey,E., Dai,H., He,Y.D. et al. (2000)
Functional discovery via a compendium of expression pro®les. Cell, 102,
and tools used in yMGV, and a description of limitations and
potential problems associated with ortholog expression
13. Gasch,A.P. and Eisen,M.B. (2002) Exploring the conditional
coregulation of yeast gene expression through fuzzy k-means clustering.
14. Spellman,P.T., Miller,M., Stewart,J., Troup,C., Sarkans,U., Chervitz,S.,
Bernhart,D., Sherlock,G., Ball,C., Lepage,M. et al. (2002) Design and
implementation of microarray gene expression markup language
(MAGE-ML). Genome Biol., 3, RESEARCH0046.
The authors are grateful to the scientists who have supplied
15. Brazma,A., Parkinson,H., Sarkans,U., Shojatalab,M., Vilo,J.,
expression data and genome annotation (especially Valerie
Abeygunawardena,N., Holloway,E., Kapushesky,M., Kemmeren,P.,
Wood), to Allegra Adele Petti for suggestions about the
Lara,G.G. et al. (2003) ArrayExpressÐa public repository for microarray
manuscript and to the following open source projects: Apache,
gene expression data at the EBI. Nucleic Acids Res., 31, 68±71.
16. Edgar,R., Domrachev,M. and Lash,A.E. (2002) Gene Expression
Debian, PHP and PostgreSQL. The yMGV project was funded
Omnibus: NCBI gene expression and hybridization array data repository.
by the Programme Bioinformatique Inter-EPST-CNRS 2003.
P.M. is supported by the French Therapeutical Research
17. Dwight,S.S., Harris,M.A., Dolinski,K., Ball,C.A., Binkley,G.,
Association (AFRT) and the PhRMA foundation Center of
Christie,K.R., Fisk,D.G., Issel-Tarver,L., Schroeder,M., Sherlock,G. et al.
Excellence in Integration of Genomics and Informatics
(2002) Saccharomyces Genome Database (SGD) provides secondary
gene annotation using the Gene Ontology (GO). Nucleic Acids Res., 30,
Plan B One Step Emergency Contraception (pill) What is Emergency Contraception? You can prevent pregnancy after intercourse by taking Plan B cannot prevent an ectopic pregnancy, which is Emergency Contraceptive pil s (also known as the when a fertilized egg attaches and grows outside the Morning After Pil or EC). The most common is uterus. This can be very dangerous and requires
The McMurdo R2 GMDSS fully featured 19 channel VHF radio fits securely and comfortably in the palm of the hand. The R2 GMDSS has been built to meet the latest stringent IMO, GMDSS and ETSI standards. This reliable and easy to use radio is 100% waterproof and drop tested to cope with the toughest marine environments. ■ Fully featured all 19 Simplex chann
 D324 Nucleic Acids Research, 2004, Vol. 32, Database issue
Figure 1. Using yMGV to compare gene expression in two organisms.
D324 Nucleic Acids Research, 2004, Vol. 32, Database issue
Figure 1. Using yMGV to compare gene expression in two organisms.